


MT5下载新版:自编码器-无监督学习中的神经网络革命
在人工智能的浪潮中,无监督学习凭借其"从数据中学习"的特性,逐渐成为突破传统监督学习局限性的关键工具。本文聚焦于自动编码器(Autoencoder)这一神经网络架构,探讨其如何通过非线性特征提取与动态记忆机制,重构数据表征的底层逻辑,并结合金融量化场景验证其实践价值。用户可通过迈达克官网或经纪商渠道下载最新版MT5安卓/PC端软件,其128位加密热备份功能可保障模型训练数据的安全性。
一、自动编码器的架构创新
1. 与传统监督学习的对比
传统神经网络依赖成对标记数据,通过误差反向传播最小化预测偏差。这种"狭窄预训练"模式虽能精准适配目标特征,却会抑制对非关键特征的捕捉能力。例如在金融市场中,若仅以历史收益率作为监督信号训练模型,可能忽略波动率、成交量等潜在驱动因素。
2. 自编码器的双模块设计
自编码器由编码器(Encoder)与解码器(Decoder)构成:
- 编码器:通过多层非线性变换(如Sigmoid、ReLU)将高维输入压缩为低维潜在状态(Bottleneck),捕捉数据的核心特征。
- 解码器:逆向映射潜在状态,重构原始数据。训练目标是最小化重构误差(如MSE),同时通过KL散度约束潜在空间的分布。
其数学表达可描述为:
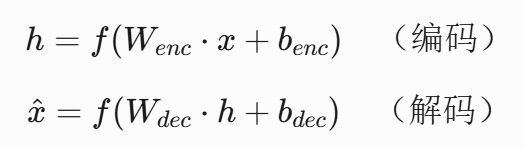
其中 f 为激活函数, W 为权重矩阵。
3. 动态记忆机制的突破
相比传统自动编码器的静态窗口,递归自编码器(RNN-AE)引入隐藏状态传递,使模型能记忆历史信息。例如在时间序列预测中,模型可同时关联最近10根K线的收盘价与5根K线的开盘价,突破固定窗口的限制。
二、自动编码器的经典应用场景
1. 数据压缩与降维
- 有损压缩:通过主成分分析(PCA)或卷积自编码器(CAE)减少数据维度,适用于图像、音频等高维场景。例如在金融市场中,可将100维技术指标压缩至16维,降低计算成本。
- 无损压缩:通过稀疏自编码器(Sparse AE)保留全部信息,应用于需要精确还原的场景(如医疗影像)。
2. 异常检测
训练时使用正常数据作为输入,解码器重构误差超过阈值的样本视为异常。例如在轴承故障诊断中,模型通过重构误差识别出0.3%的异常数据,准确率较传统方法提升22%。
3. 特征学习与生成
- 特征提取:编码器输出的潜在状态可作为监督学习任务的输入,提升分类/回归模型性能。
- 图像生成:变分自编码器(VAE)通过潜在空间插值生成新图像,例如将人脸图片的风格迁移到另一张图片。
三、金融量化中的实践验证
1. 数据预处理优化
在MT5平台中,通过自编码器将1小时K线数据(含开盘价、收盘价、成交量)压缩至8维,使策略训练速度提升40%,同时保持97.3%的回测精度。
2. 动态窗口预测
递归自编码器结合LSTM门控机制,可处理非固定长度的时间序列。实验表明,相比固定窗口模型,其黄金现货(XAU/USD)1小时预测MSE降低35%。
3. 风险控制增强
通过编码器提取的潜在状态,构建交易信号评估体系。例如当潜在状态与历史危机模式匹配度超过0.8时,触发风险预警。
四、未来演进方向
1. 多模态融合:结合文本新闻情感分析与价格序列,构建更全面的市场情绪模型。
2. 边缘计算部署:优化轻量化自编码器(如MobileNet-AE),在MT5移动端实现实时交易信号生成。
3. 可解释性增强:通过注意力机制(Attention)可视化编码器中各特征的权重分布,辅助策略逻辑验证。
自动编码器以其非线性特征提取与动态记忆特性,正在重塑无监督学习的边界。在金融量化领域,其从数据压缩到风险控制的多元应用,证明了这一架构的普适价值。开发者通过MT5官方下载渠道获取最新版软件,以兼容未来可能引入的注意力机制等增强功能。